
このブログ記事では、Stable Diffusion 3 Medium(SD3 Medium)をWindows版ローカル環境(ComfyUI)で実装し、画像生成を行うまでの手順を詳細に解説します。
SD3 Mediumは、Stability AIがリリースした最新のオープンソース画像生成AIです。従来のStable Diffusionよりも軽量で扱いやすく、高性能な画像生成を実現します。本記事では、SD3 Mediumのモデルダウンロードから、ComfyUIの導入、ワークフローのロード、画像生成まで、必要なステップを画像付きで分かりやすく説明します。
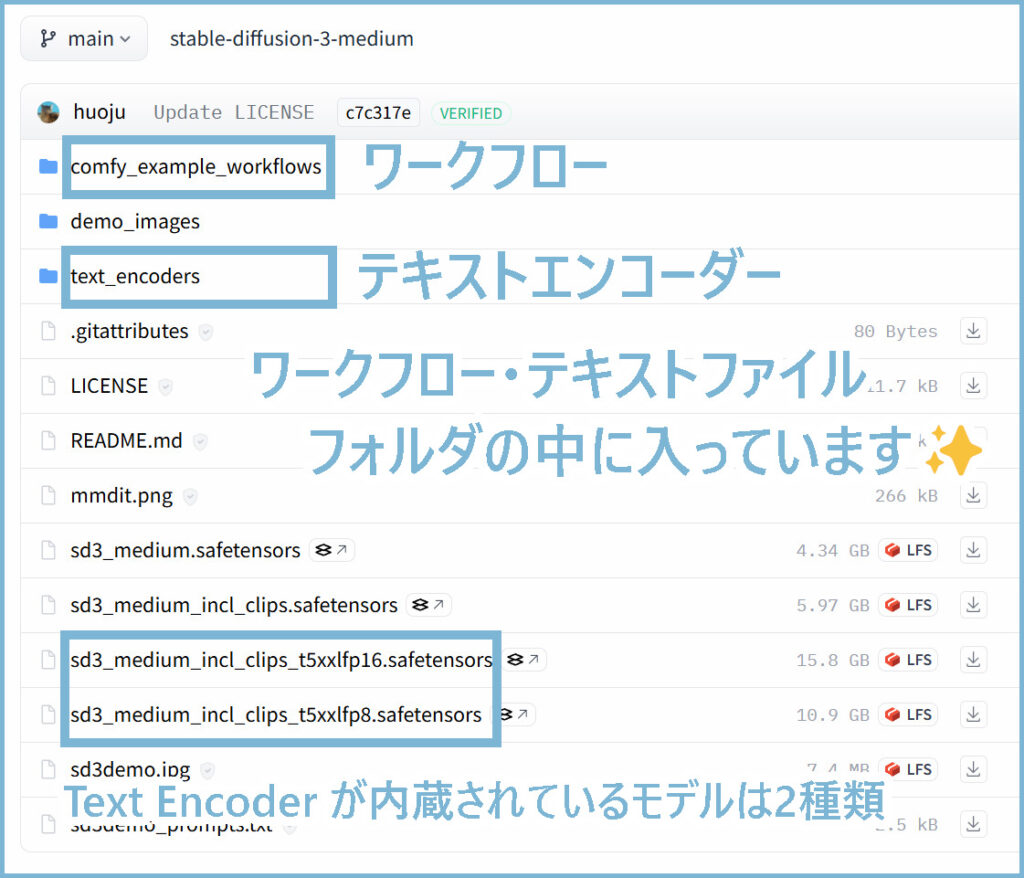
1. Hugging Faceからモデルを取得
- Hugging Faceのページへアクセスします。
https://huggingface.co/stabilityai/stable-diffusion-3-medium - ログインし、利用規約に同意します。 “stable-diffusion-3-medium”リポジトリから以下のいずれかのモデルをダウンロードします。
sd3_medium.safetensorssd3_medium_incl_clips_t5xxlfp16.safetensorssd3_medium_incl_clips_t5xxlfp8.safetensors
Text Encoder が内蔵されているモデルは次の2種類sd3_medium_incl_clips_t5xxlfp16.safetensorssd3_medium_incl_clips_t5xxlfp8.safetensors
sd3_medium_incl_clips_t5xxlfp8.safetensorsは、以下のユーザーにおすすめです。
シンプルで最高の結果が期待できる
メモリ使用量を抑えたい
sd3_medium_incl_clips_t5xxlfp16.safetensorsは、以下のユーザーにおすすめです。
sd3_medium_incl_clips_t5xxlfp8.safetensors と同構成だが、T5 部分の圧縮率が低い
VRAM容量が十分にある
わずかに高い画質を求める - ワークフローサンプルjson
sd3_medium_example_workflow_basic.jsonをダウンロードします - テキストエンコーダー
clip_g.safetensorsclip_l.safetensorst5xxl_fp8_e4m3fn.safetensorsまたはt5xxl_fp16.safetensors
2 ComfyUIの実装
Gitのダウンロードとインストール
Gitをまだインストールしていない場合は、以下のURLからダウンロードしてインストールします。
https://git-scm.com
ComfyUIのダウンロード
以下のURLからComfyUIをダウンロードします。
https://github.com/comfyanonymous/ComfyUI/releases
3 モデルの配置
ダウンロードしたComfyUIを解凍し、以下のディレクトリに配置します。
この手順は、SD3 Mediumを使って画像生成を行うためにSD3 MediumモデルとテキストエンコーダーをComfyUIが認識できるように配置する手順です。
- SD3 Mediumモデルの配置ダウンロードしたSD3 Mediumモデルファイル
(例:sd3_medium_incl_clips_t5xxlfp8.safetensors)を以下のディレクトリに配置します。ComfyUI_windows_portable\modelsこのディレクトリは、ComfyUIが起動時に自動的にモデルファイルを検索する場所です。 - テキストエンコーダーの配置テキストエンコーダーが必要なモデルを使用する場合、以下の3つのテキストエンコーダーファイルを以下のディレクトリに配置する必要があります。
ComfyUI_windows_portable\ComfyUI\models\clipclip_g.safetensorsclip_l.safetensorst5xxl_fp8_e4m3fn.safetensorsまたはt5xxl_fp16.safetensors
4 ComfyUI Managerの導入
ComfyUI Managerのクローン方法
コマンドを開き、
Windowsキー + R を押して、「cmd」と入力し、Enterキーを押す。
スタートメニュー から「コマンドプロンプト」を選択する。
以下のコマンドを実行して、ComfyUI Managerをクローンします。
git clone https://github.com/ltdrdata/ComfyUI-Manager.gitこのコマンドを実行すると、ComfyUI-Manager という名前のフォルダが作成されます。
ComfyUI Manager をクローンしたフォルダ内(ComfyUI-Manager)で、以下のコマンドを実行します。
node install.jsこのコマンドを実行すると、ComfyUI Managerに必要なファイルがインストールされます。
ComfyUI の起動
ComfyUI_windows_portable フォルダにある「run_nvidia_gpu」バッチファイルをダブルクリックして、ComfyUI を起動します。
SD3 用ワークフローのロード
ComfyUI 画面左上の「Load Workflow」ボタンをクリックし、ダウンロードした sd3_medium_example_workflow_basic.json ファイルを選択します。
4. ワークフローの更新
以下のメッセージが表示された場合は、右下の「Manager」ボタンをクリックします。
ワークフローに足りないノードがあります
ComfyUI Manager が起動し、「Update All」ボタンをクリックします。
5 画像生成
以下の手順で画像生成を実行します。
- 画面左上の「Load Checkpoint」から、ダウンロードした SD3 Medium モデルファイルを選択します。
- テキストエンコーダーが不要なモデルの場合は、「TripleCLIPLoader」ノードを削除します。
- 画面中央の「Prompt」欄に、生成したい画像の内容を入力します。
- 画面右上の「Queue Prompt」ボタンをクリックして、画像生成を実行します。
6. 生成結果の確認
生成された画像は、画面下部の「Output」パネルに表示されます。
補足:
- 上記の手順は、Windows版ローカル環境でのComfyUI実装を想定しています。
- モデルファイルやテキストエンコーダーファイルの名前は、ダウンロードしたバージョンによって異なる場合があります。
- コマンドを実行する際は、管理者権限で実行する必要があります。
- モデルファイルが正しくロードされていない可能性があります。
- ワークフローの設定が間違っている可能性があります。
お疲れさまでした!立ち上がりましたでしょうか?スクショ取り忘れて画像が少なくてごめんなさい。使い方はまたの記事で書いていこうと思います✨
私も手探り状態で生成中です、いろいろと助言もらえると助かります。よろしくお願いします(≧▽≦)
プロンプト:ミッドジャーニーなどの文章形式のプロンプトのにした方が綺麗な画ができました。
ミッドジャーニーの記事も参考にしてみてください♪